Apache Nutch & Solr
Apache Nutch and Apache Solr are projects from Apache Lucene search engine. Nutch is an open source crawler which provides the Java library for crawling, indexing and database storage. Solr is an open source search platform which provides full-text search and integration with Nutch. The following contents are steps of setting up Nutch and Solr for crawling and searching.
Environment Setup
Operating System
Ubuntu 20.04.1 64bit running on VMware with 4 cores and 8GB memory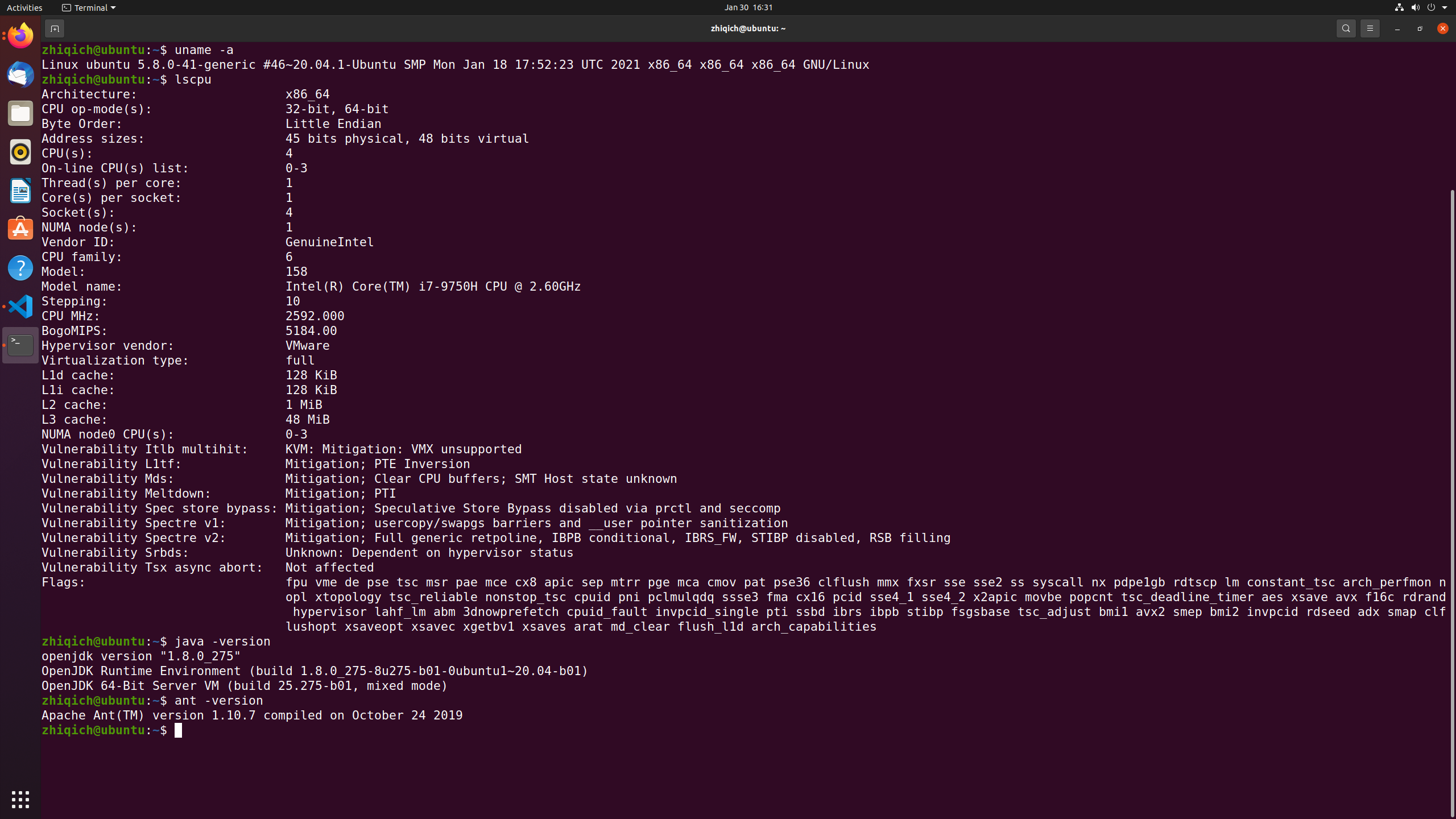
Java
Java Runtime/Development Environment is JDK 1.8/Java 8
Installed by command line
1 | sudo apt-get install openjdk-8-jdk |
Installation can be checked by
1 | java -version |
and the result in command line should be
1 | openjdk version "1.8.0_275" |
After installation, add the JAVA_HOME parameter to the environment
1 | vim ~/.bashrc |
If successful, the result should be like
1 | echo $JAVA_HOME |
Localhost
Check the localhost file
1 | vim /etc/hosts |
and there should be a line for local ip address similar to
1 | 127.0.0.1 localhost |
Nutch Installation
Download a binary package of Apache Nutch version 1.15 from Apache Archives (https://archive.apache.org/dist/nutch/1.15/)\
Unzip the package and get the folder apache-nutch-1.15/
To verify the installation, run command line
1 | cd apache-nutch-1.15/ |
the result should be similar to
1 | nutch 1.15 |
Solr Setup
Download
Download a binary package of Apache Solr version 7.3.1 from Apache Archives (https://archive.apache.org/dist/lucene/solr/7.3.1/)\
Unzip the package and get the folder solr-7.3.1/
Download corresponding Nutch schema from https://raw.githubusercontent.com/apache/nutch/master/src/plugin/indexer-solr/schema.xml
Set Solr Core
Create resources for a new Solr core nutch
1 | cd solr-7.3.1/ |
Copy the downloaded schema to core nutch configuration (instead of the schema directly from downloaded Nutch package, otherwise occurs fieldType “pdates” error)
1 | cp ../../Downloads/schema.xml server/solr/configsets/nutch/conf/ |
Delete the schema template
1 | rm server/solr/configsets/nutch/conf/managed-schema |
Start Solr server
1 | bin/solr start |
Create Solr core nutch
1 | bin/solr create -c nutch -d server/solr/configsets/nutch/conf/ |
Test the server by launching http://localhost:8983/solr/#/\
Stop Solr server (after the crawling and searching)
1 | bin/solr stop |
Nutch Integration
The index writer configuration file for Nutch version 1.15 is conf/index-writers.xml in which the format and meta data can be modified
Crawl Setup
Crawl Property
Default crawl properties is set in conf/nutch-default.xml which defines properties for file, http, plugin and so on
Custom crawl properties can be set in conf/nutch-site.xml and there are two must-have properties to set
1 |
|
The indexer-solr is a must in plugin.includes property which is the default setting in conf/nutch-default.xml
Seed URLs
Create a URL seed list file by
1 | cd apache-nutch-1.15/ |
One URL per line for each site to crawl and it is important to design the seed list to avoid unnecessary pages and reduce crawling time
For example, if the crawling target is the list of professors and students major in computer science, the seed list can be chosen from faculty and student pages of universities
1 | https://www.cc.gatech.edu/people/faculty |
Regular Expression Filters can be configured in conf/regex-urlfilter.txt to limit the crawling range
Crawling
Crawl Database
Databases are used in crawling to store fetched information and the URL queue
Crawl database (crawldb) is provided by Nutch to store URL information obtained by Nutch (seeded or fetched) including the status and the time fetched
Link database (linkdb) is provided by Nutch to store the links to each URL including the source URL and the anchor text of each link
External databases can also be integrated to Nutch but need to configure
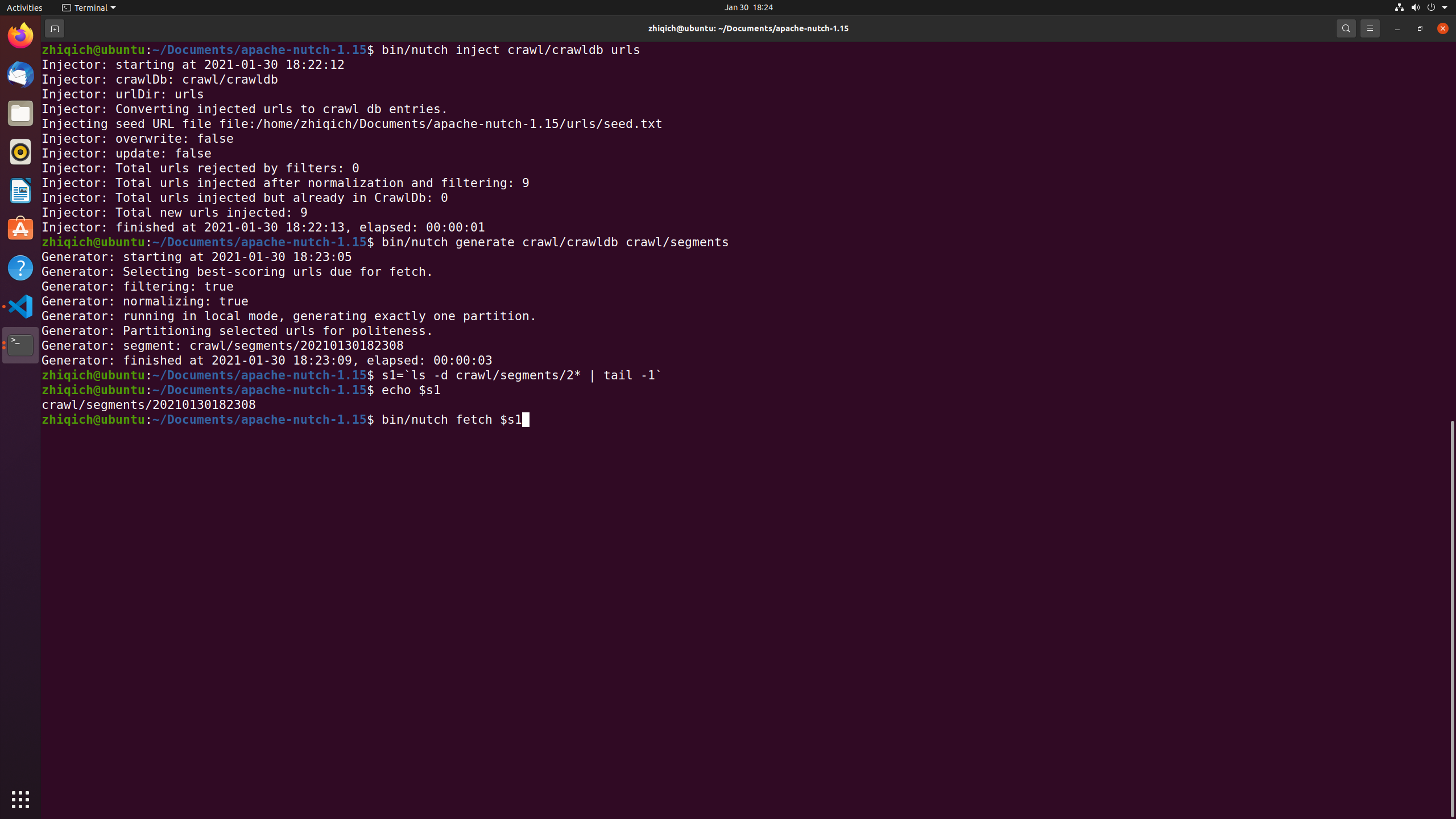
Before fetching URLs, insert the seed list to initiate crawldb
1 | bin/nutch inject crawl/crawldb urls |
Fetching
First generate a fetch list (URL queue) from the database
1 | bin/nutch generate crawl/crawldb crawl/segments |
The list will be placed in a newly created segment directory names by the timestamp when it is created
Create the abbreviation of the most recent fetch list to make the later expression simple
1 | s1=`ls -d crawl/segments/2* | tail -1` |
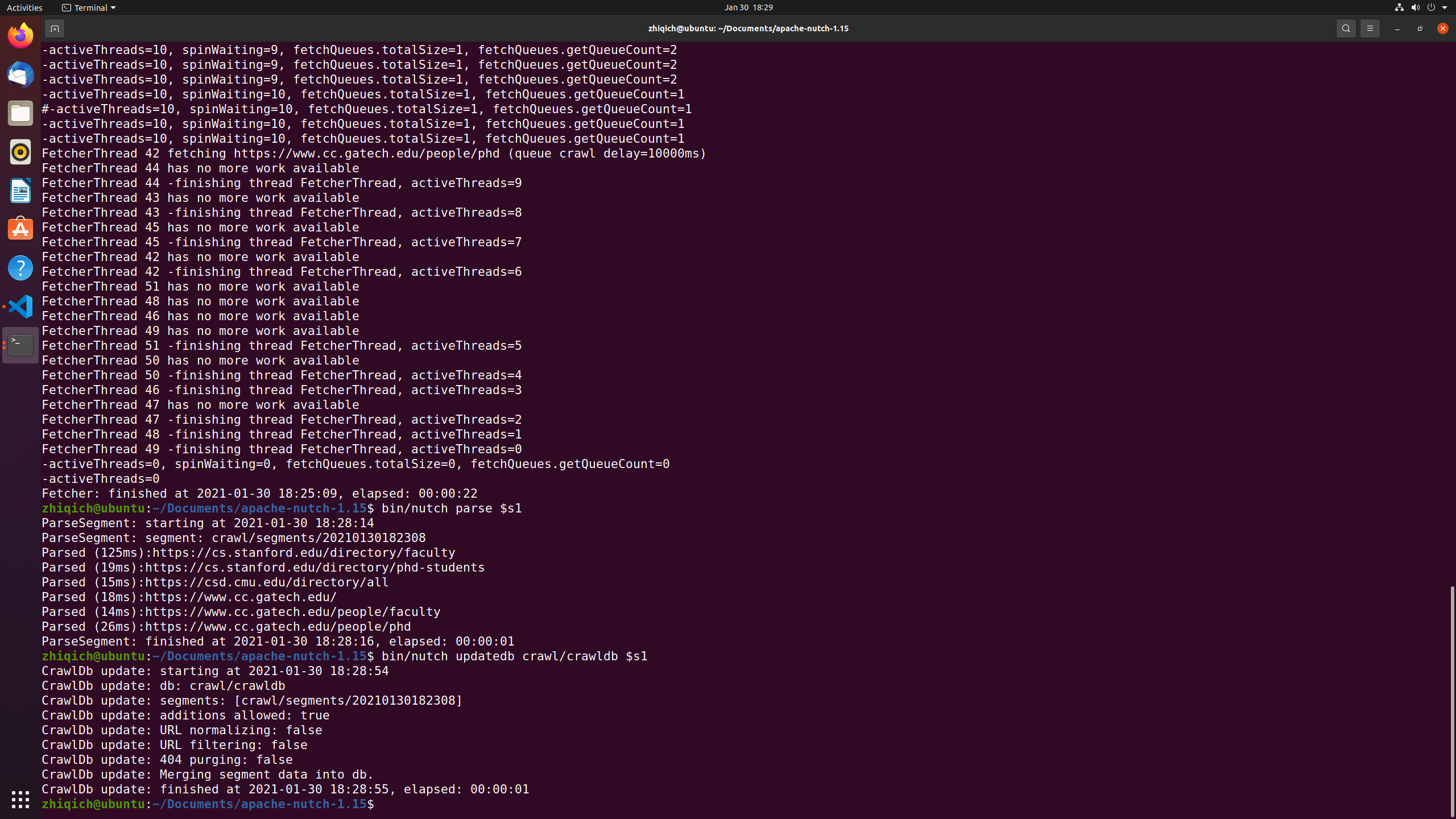
Run the fetcher on the segment
1 | bin/nutch fetch $s1 |
The fetching time will depend on the length of the URL list and the number of links in each URL
Parse the entries after fetching
1 | bin/nutch parse $s1 |
Update the database with the results of the fetch
1 | bin/nutch updatedb crawl/crawldb $s1 |
After the first round fetching, the database contains both the initial pages and the newly discovered pages linked to the seed URLs so that a second round fetching can be further processed
Number of top-scoring pages can be chosen when generating the fetching list by the flag -topN
1 | bin/nutch generate crawl/crawldb crawl/segments -topN 1000 |
Indexing
Invert all of the links
1 | bin/nutch invertlinks crawl/linkdb -dir crawl/segments |
Index all the resources by Solr (use index instead of solrindex which is deprecated)
1 | bin/nutch index crawl/crawldb/ -linkdb crawl/linkdb/ -dir crawl/segments -filter -normalize -deleteGone |
There are more options for the index command but may not be applied
1 | Usage: Indexer (<crawldb> | -nocrawldb) (<segment> ... | -dir <segments>) [general options] |
Usually deleting duplication is necessary when indexing, but Solr will handle it automatically
1 | Usage: bin/nutch dedup <crawldb> [-group <none|host|domain>] [-compareOrder <score>,<fetchTime>,<httpsOverHttp>,<urlLength>] |
After done searching, clean Solr to maintain a healthier quality of index
1 | bin/nutch clean crawl/crawldb/ |
Script
Crawl script is provide by Nutch to allow more options and parameter modification for crawling, but it may not be so useful in crawling a small number of URLs when step-by-step operation and monitor are necessary
1 | Usage: crawl [options] <crawl_dir> <num_rounds> |
Searching
After crawling and indexing, launch Solr quey console (http://localhost:8983/solr/#/nutch/query)\
Text queries in the q block using key-value pairs, for example, search pages with key word “system” in “content”
1 | content:system |
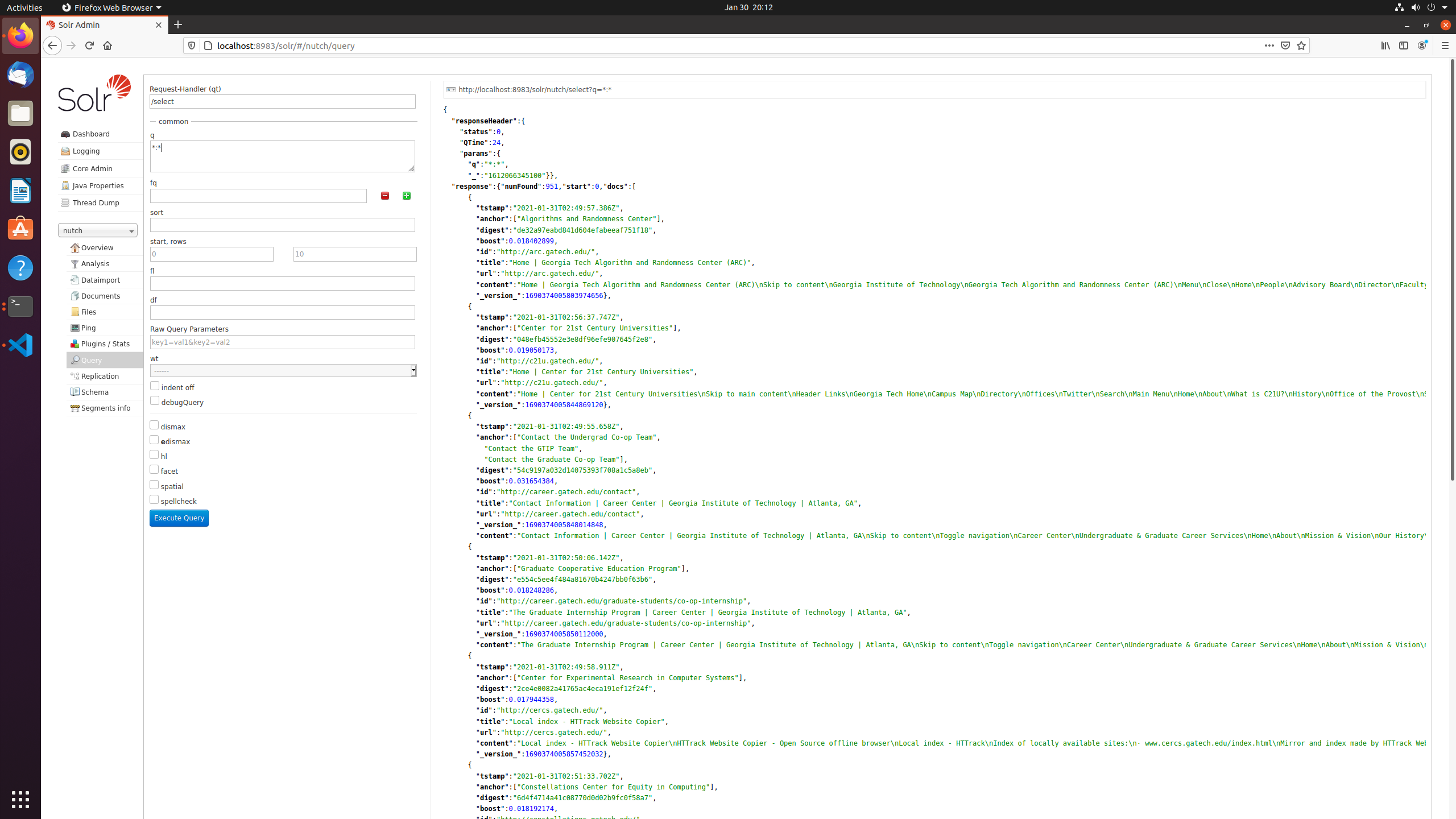
Searching range and other query parameters can be set with provided options